open_clip - 欢迎使用 OpenAI 的CLIP(对比语言-图像预训练)的开源实现。
打开剪辑
欢迎来到OpenAI的CLIP(对比语言图像预训练)的开源实现。
该存储库的目标是启用具有对比图像-文本监督的训练模型,并研究其属性,例如对分布偏移的鲁棒性。我们的起点是 CLIP 的实现,当在同一数据集上训练时,它与原始 CLIP 模型的准确性相匹配。具体来说,在OpenAI的1500万张YFCC图像子集上使用我们的代码库训练的ResNet-50模型在ImageNet上实现了32.7%的top-1准确率。OpenAI的CLIP模型在YFCC的同一子集上训练时达到31.3%。为了便于实验,我们还提供了用于对概念字幕数据集中的 300 万张图像进行训练的代码,其中使用我们的代码库训练的 ResNet-50x4 达到 22.2% top-1 ImageNet 准确率。
我们通过对与OpenAI的LAION-400M和更大的LAION-2B超集相当的数据集进行复制研究来进一步研究。
我们培训过:
- LAION-400M 上的 ViT-B/32 准确率为 62.9%,与 OpenAI 在 ImageNet1k 上的 63.2% 零镜头 top-1 相当。
- LAION-2B上的ViT-B/32,精度为66.6%。
- LAION-400M 上的 ViT-B/16 实现了 67.1% 的准确率,低于 OpenAI 的 68.3%(此处测量,纸张为 68.6%)
- 在LAION-400M上,ViT-B/16+ 240x240(比B/16 224x224多~50%),精度达到69.2%
- LAION-400M 上的 ViT-L/14 准确率为 72.77%,而 OpenAI 的准确度为 75.5%(此处测量,纸张为 75.3%)
- LAION-2B上的ViT-L/14的准确率为75.3%,而OpenAI的准确率为75.5%(此处测量,纸张为75.3%)
- LAION-2B上的ViT-H / 14,精度为78.0。迄今为止发布开源权重的最佳 in1k 零镜头。
- LAION-2B上的ViT-g/14,精度为76.6。这是在减少的时间表上进行训练的,与400M模型相同的样本。
正如我们在下面更详细地描述的那样,中等精度状态下的 CLIP 模型已经允许我们对较大 CLIP 模型的鲁棒性得出结论,因为这些模型遵循可靠的缩放定律。
此代码库正在进行中,我们邀请所有人做出贡献,使其更易于访问和有用。将来,我们计划添加对 TPU 训练的支持并发布更大的模型。我们希望这个代码库有助于和促进对比图像文本学习的进一步研究。如果你有任何其他要求或建议,请提交问题或发送电子邮件。
请注意,部分建模和标记器代码是OpenAI官方存储库的改编。
src/open_clip/
方法
 |
|---|
| 图片来源:https://github.com/openai/CLIP |
用法
pip install open_clip_torch
import torch
from PIL import Image
import open_clip
model, _, preprocess = open_clip.create_model_and_transforms('ViT-B-32-quickgelu', pretrained='laion400m_e32')
tokenizer = open_clip.get_tokenizer('ViT-B-32-quickgelu')
image = preprocess(Image.open("CLIP.png")).unsqueeze(0)
text = tokenizer(["a diagram", "a dog", "a cat"])
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
print("Label probs:", text_probs) # prints: [[1., 0., 0.]]要有效地计算数十亿个嵌入,你可以使用支持 openclip 的剪辑检索。
微调分类任务
此存储库专注于训练 CLIP 模型。要在下游分类任务(如 ImageNet)上微调经过训练的零镜头模型,请参阅我们的其他存储库:WiSE-FT。WiSE-FT 存储库包含我们关于零镜头模型的鲁棒微调的论文的代码,其中我们介绍了一种微调零镜头模型的技术,同时在分布偏移下保持鲁棒性。
数据
要将数据集下载为网络数据集,我们建议使用 img2dataset
概念性字幕
OpenCLIP 读取包含两列的 CSV 文件:图像路径和文本标题。列的名称作为参数传递给 。
main.py
该脚本将收集概念字幕图像。首先,下载概念字幕 URL,然后从我们的存储库运行脚本:
src/data/gather_cc.py
python3 src/data/gather_cc.py path/to/Train_GCC-training.tsv path/to/Validation_GCC-1.1.0-Validation.tsv我们的训练集包含 2.89M 张图像,我们的验证集包含 13K 张图像。
YFCC和其他数据集
除了如上所述通过CSV文件指定训练数据外,我们的代码库还支持webdataset,建议将其用于更大规模的数据集。预期的格式是一系列文件。每个文件都应包含两个用于每个训练示例的文件,一个用于图像,一个用于相应的文本。这两个文件应具有相同的名称,但扩展名不同。例如,可能包含 和 等文件。你可以在 https://github.com/webdataset/webdataset 了解更多信息。我们使用每个文件有 1,000 个数据点,我们使用 tarp 创建这些文件。
.tar
.tar
shard_001.tar
abc.jpg
abc.txt
webdataset
.tar
你可以从多媒体共享资源下载YFCC数据集。与OpenAI类似,我们使用YFCC的一个子集来达到上述准确性数字。此子集中的图像索引位于 OpenAI 的 CLIP 存储库中。
训练剪辑
安装
我们建议你首先使用以下内容创建虚拟环境:
python3 -m venv .env source .env/bin/activate pip install -U pip
然后,你可以安装 openclip 以使用 进行训练。
pip install 'open_clip_torch[training]'
发展
如果要更改贡献代码,可以关闭 openclip,然后在 openclip 文件夹中运行(创建 virtualenv 后)
make install
按照 https://pytorch.org/get-started/locally/ 安装pip PyTorch
测试可以运行然后
make install-test
make test
python -m pytest -x -s -v tests -k "training"运行特定测试
在引入新模型时,可以生成新的输出预期数据。
python tests/util_test.py --model=xlm-roberta-large-ViT-H-14
你可以运行安装培训部门
make install-training
单进程运行代码示例:
python -m training.main \
--save-frequency 1 \
--zeroshot-frequency 1 \
--report-to tensorboard \
--train-data="/path/to/train_data.csv" \
--val-data="/path/to/validation_data.csv" \
--csv-img-key filepath \
--csv-caption-key title \
--imagenet-val=/path/to/imagenet/root/val/ \
--warmup 10000 \
--batch-size=128 \
--lr=1e-3 \
--wd=0.1 \
--epochs=30 \
--workers=8 \
--model RN50注意:是用于零镜头评估的 ImageNet 验证集的路径,而不是训练集!如果你不想在整个训练过程中在 ImageNet 上执行零镜头评估,则可以删除此参数。请注意,该文件夹应包含子文件夹。如果没有,请使用此脚本。
imagenet-val
val
多图形用户界面及更高版本
此代码已经过多达 1024 架 A100 的实战测试,并为分布式训练提供了多种解决方案。我们包括对 SLURM 集群的本机支持。
随着用于训练的设备数量的增加,logit 矩阵的空间复杂性也会增加。使用朴素的全聚集方案,空间复杂性将是 .相反,如果使用标志和,复杂性可能会变得有效的线性。这种改变导致一对一的数值结果作为朴素方法。
O(n^2)
--gather-with-grad
--local-loss
时代
对于较大的数据集(例如Laion2B),我们建议将--train-num-samples设置为低于完整纪元的值,例如与--dataset-resampled一起设置为纪元的1/16,以使用替换进行采样。这允许频繁的检查点更频繁地进行评估。
--train-num-samples 135646078
单节点
我们利用 来启动分布式作业。以下内容在包含 4 个 GPU 的节点上启动作业:
torchrun
cd open_clip/src
torchrun --nproc_per_node 4 -m training.main \
--train-data '/data/cc12m/cc12m-train-{0000..2175}.tar' \
--train-num-samples 10968539 \
--dataset-type webdataset \
--batch-size 320 \
--precision amp \
--workers 4 \
--imagenet-val /data/imagenet/validation/多节点
只要用户包含有关节点数和主机节点数的信息,上面的相同脚本就可以工作。
cd open_clip/src
torchrun --nproc_per_node=4 \
--rdzv_endpoint=$HOSTE_NODE_ADDR \
-m training.main \
--train-data '/data/cc12m/cc12m-train-{0000..2175}.tar' \
--train-num-samples 10968539 \
--dataset-type webdataset \
--batch-size 320 \
--precision amp \
--workers 4 \
--imagenet-val /data/imagenet/validation/口水
这可能是最容易使用的解决方案。以下脚本用于训练我们最大的模型:
#!/bin/bash -x
#SBATCH --nodes=32
#SBATCH --gres=gpu:4
#SBATCH --ntasks-per-node=4
#SBATCH --cpus-per-task=6
#SBATCH --wait-all-nodes=1
#SBATCH --job-name=open_clip
#SBATCH --account=ACCOUNT_NAME
#SBATCH --partition PARTITION_NAME
eval "$(/path/to/conda/bin/conda shell.bash hook)" # init conda
conda activate open_clip
export CUDA_VISIBLE_DEVICES=0,1,2,3
export MASTER_PORT=12802
master_addr=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | head -n 1)
export MASTER_ADDR=$master_addr
cd /shared/open_clip
export PYTHONPATH="$PYTHONPATH:$PWD/src"
srun --cpu_bind=v --accel-bind=gn python -u src/training/main.py \
--save-frequency 1 \
--report-to tensorboard \
--train-data="/data/LAION-400M/{00000..41455}.tar" \
--warmup 2000 \
--batch-size=256 \
--epochs=32 \
--workers=8 \
--model ViT-B-32 \
--name "ViT-B-32-Vanilla" \
--seed 0 \
--local-loss \
--gather-with-grad从检查点恢复:
python -m training.main \
--train-data="/path/to/train_data.csv" \
--val-data="/path/to/validation_data.csv" \
--resume /path/to/checkpoints/epoch_K.pt使用预先训练的语言模型作为文本编码器进行训练:
如果你希望使用不同的语言模型作为 CLIP 的文本编码器,则可以通过使用拥抱面模型配置之一并分别将其分词器作为 and 参数传入来实现。目前我们只支持RoBERTa(“test-roberta”配置),但是添加新模型应该是微不足道的。你还可以使用参数确定从末尾开始要保持未冻结的图层数。下面是一个使用 RoBERTa LM 训练 CLIP 的示例命令,该 LM 已解冻其最后 10 层:
src/open_clip/model_configs
--model
--hf-tokenizer-name
--lock-text-unlocked-layers
python -m training.main \
--train-data="pipe:aws s3 cp s3://s-mas/cc3m/{00000..00329}.tar -" \
--train-num-samples 3000000 \
--val-data="pipe:aws s3 cp s3://s-mas/cc3m/{00330..00331}.tar -" \
--val-num-samples 10000 \
--dataset-type webdataset \
--batch-size 256 \
--warmup 2000 \
--epochs 10 \
--lr 5e-4 \
--precision amp \
--workers 6 \
--model "roberta-ViT-B-32" \
--lock-text \
--lock-text-unlocked-layers 10 \
--name "10_unfrozen" \
--report-to "tensorboard" \损耗曲线
在具有 8 个 GPU 的计算机上运行时,该命令应为概念字幕生成以下训练曲线:
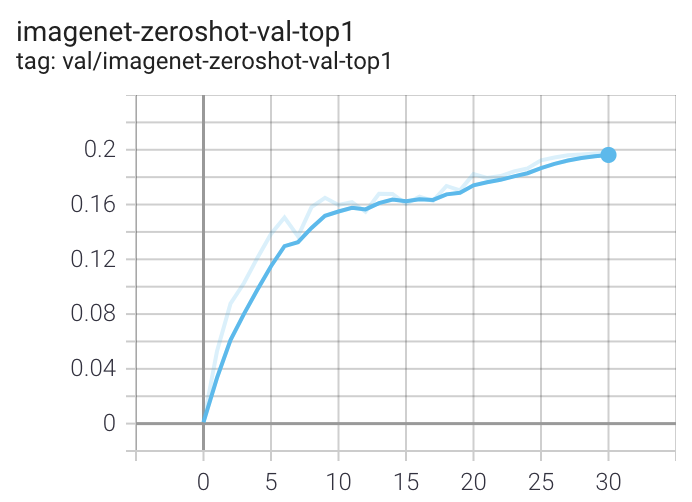
概念字幕的更详细曲线在 /docs/clip_conceptual_captions.md 中给出。
在 YFCC 上训练 RN50 时,使用与上述相同的超参数,但 和 除外。
lr=5e-4
epochs=32
请注意,要使用其他模型,如 或 或 或 ,请使用 指定 。
ViT-B/32
RN50x4
RN50x16
ViT-B/16
--model RN50x4
启动张量板:
tensorboard --logdir=logs/tensorboard/ --port=7777评估/零射击
评估本地检查点:
python -m training.main \
--val-data="/path/to/validation_data.csv" \
--model RN101 \
--pretrained /path/to/checkpoints/epoch_K.pt在 ImageNet 零镜头预测上评估托管的预训练检查点:
python -m training.main \
--imagenet-val /path/to/imagenet/validation \
--model ViT-B-32-quickgelu \
--pretrained laion400m_e32预训练模型详细信息
LAION-400M - https://laion.ai/laion-400-open-dataset
我们正在努力使用同等大小(和开放)的LAION-400M数据集重现OpenAI的ViT结果。训练权重可以在版本 v0.2 中找到。
LAION400M砝码已在JOWELS超级计算机上进行了训练(请参阅下面的致谢部分)。
ViT-B/32 224x224
我们在ViT-B/32上复制了OpenAI的结果,达到了62.96%的ImageNet-1k零拍精度。
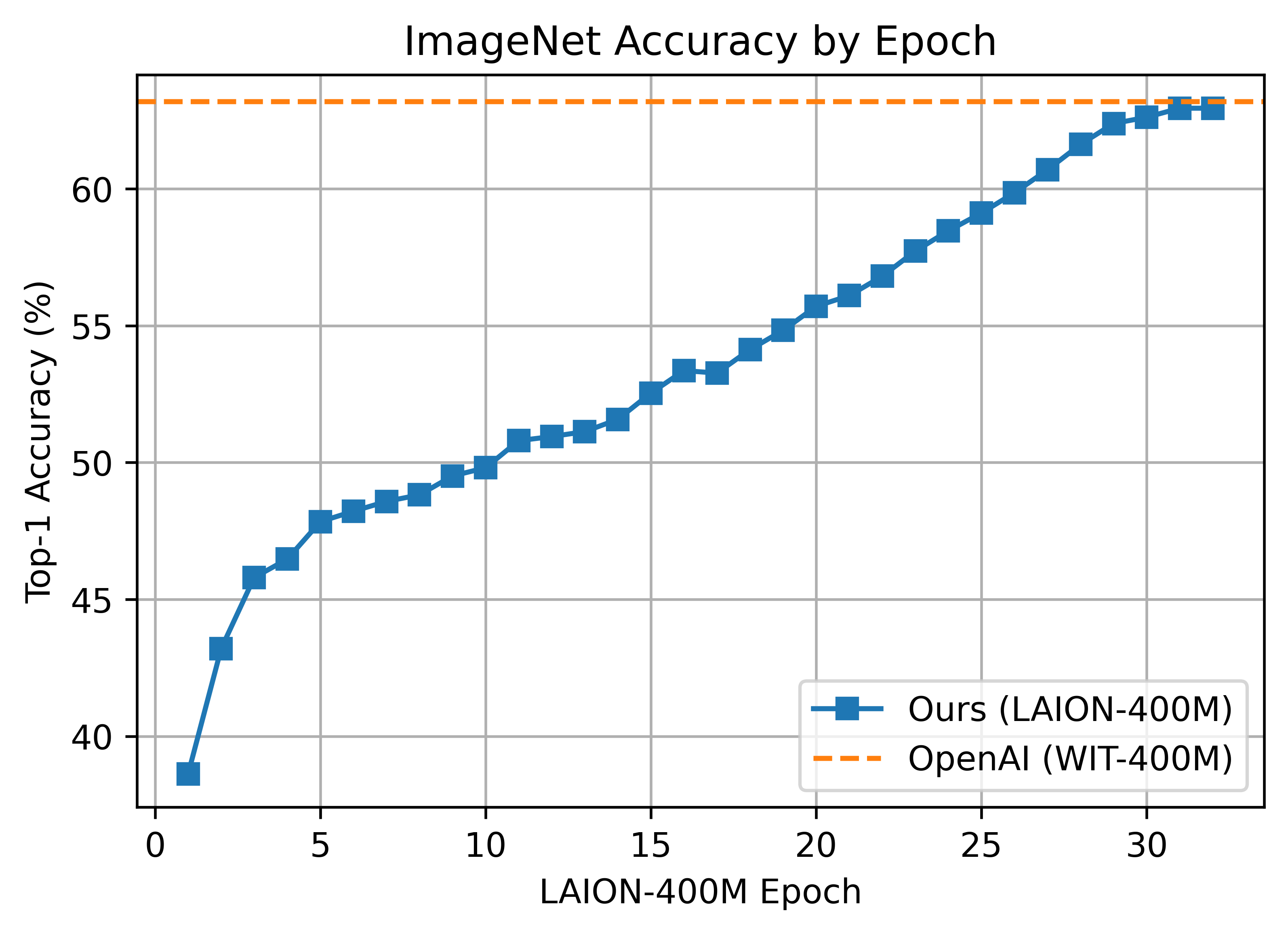
零镜头比较(由Andreas Fürst提供)
ViT-B/32 使用 128 个 A100 (40 GB) GPU 训练了 ~36 小时,4600 个 GPU 小时。每个 GPU 批处理大小为 256,全局批处理大小为 32768。256 远低于它可能的 (~320-384),因为在移动到“局部”对比损失之前最初是大小。
ViT-B/16 224x224
B/16 LAION400M 训练达到了 ImageNet-1k 零镜头验证得分 67.07 的前 1 名。
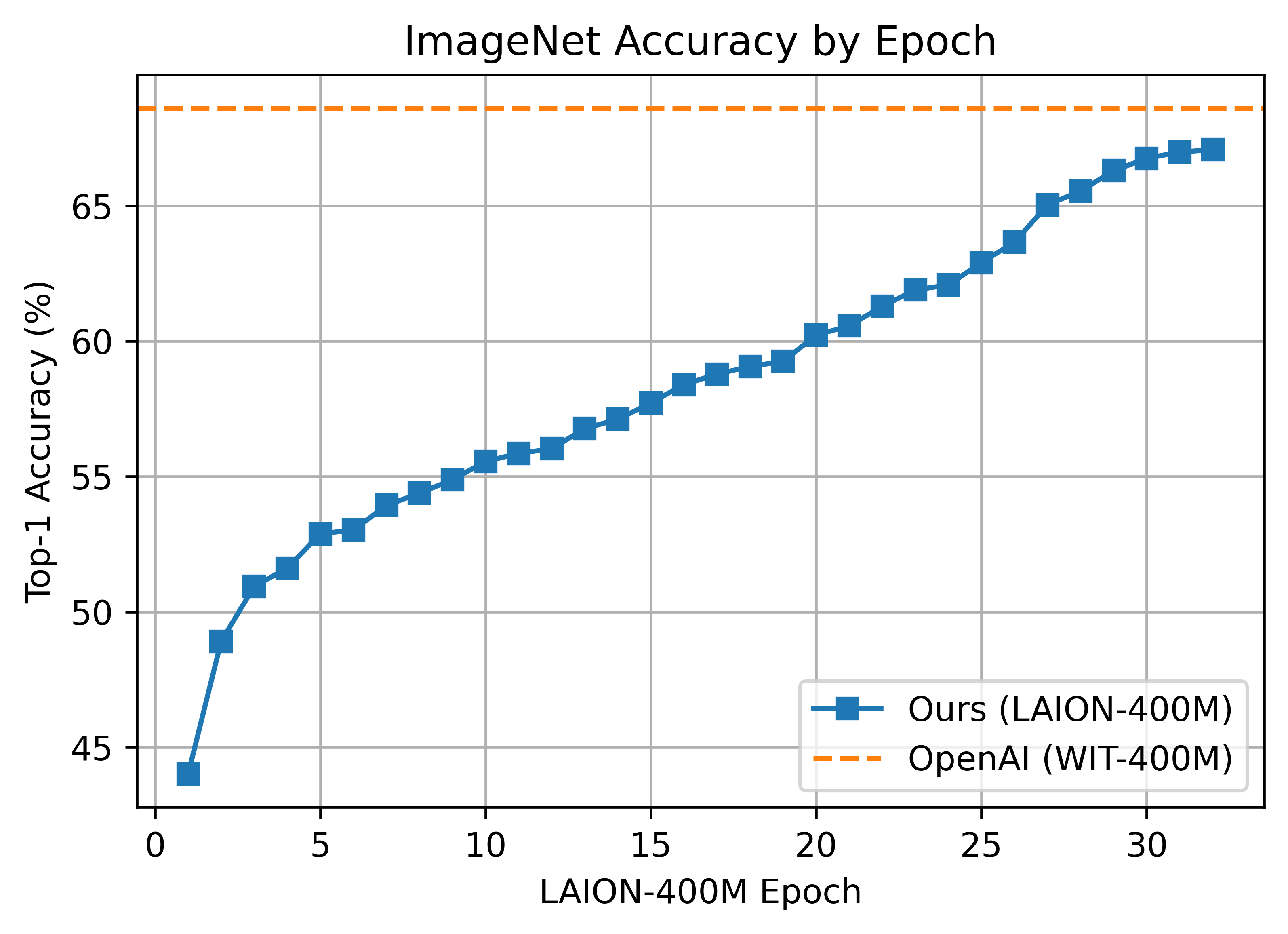
这是使用更新的 webdataset 0.2.x 代码的第一个主要训练会话。发现了一个错误,该错误阻止了每个纪元在节点/工作线程之间正确洗牌分片。这在训练过程中(纪元 26)中途修复,但可能会产生影响。
ViT-B/16 使用 176 个 A100 (40 GB) GPU 训练了 ~61 小时,10700 个 GPU 小时。每个 GPU 的批大小为 192,全局批大小为 33792。
ViT-B/16+ 240x240
B/16+ 240x240 LAION400M 训练达到了 ImageNet-1k 零镜头验证得分 69.21 的前 1 名。
该型号与 B/16 的深度相同,但增加了
- 视野宽度从 768 -> 896
- 文本宽度从 512 -> 640
- 分辨率 224x224 -> 240x240(196 -> 225 个代币)
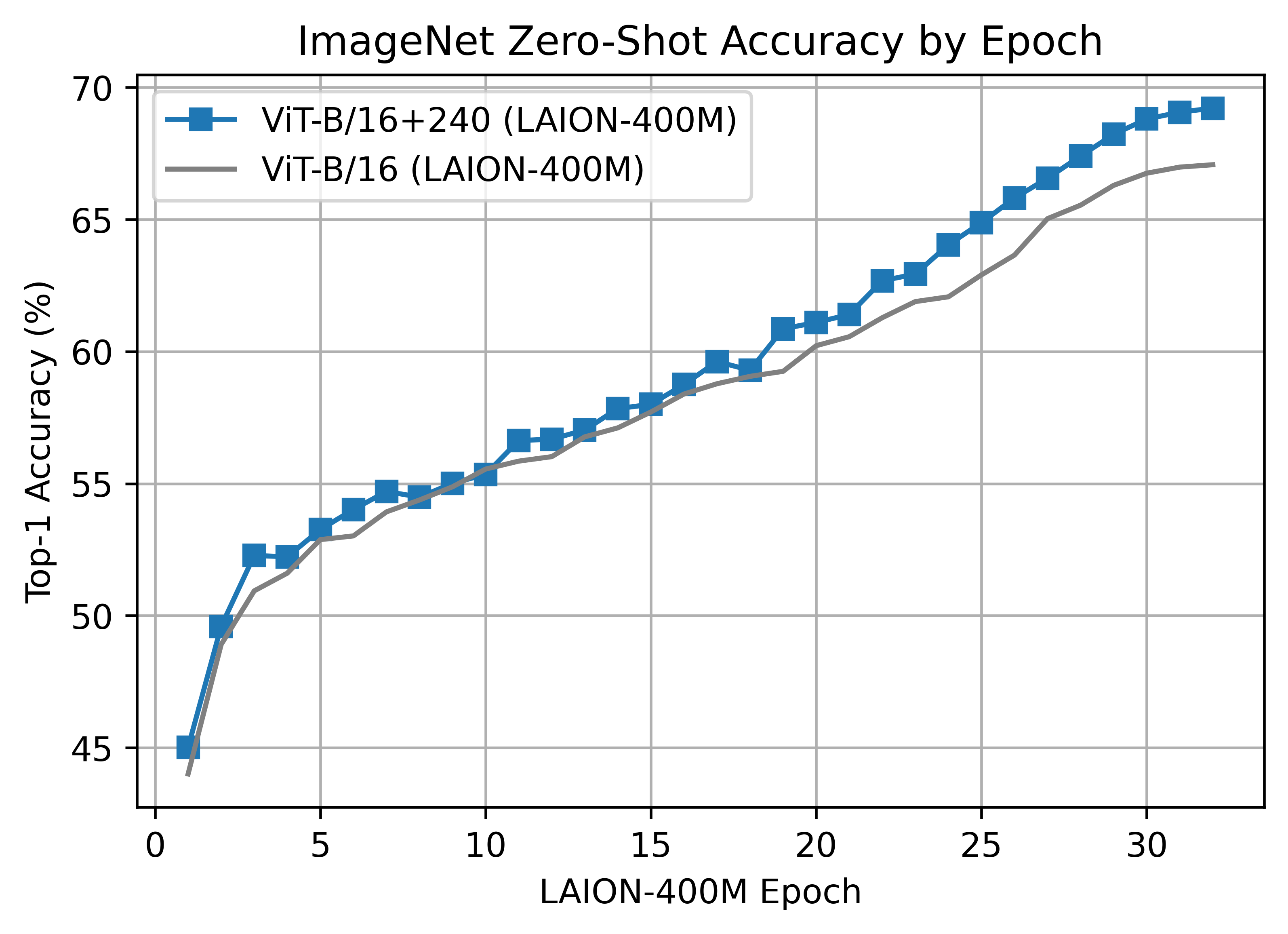
与上面的 B/16 运行不同,此模型是干净的运行,没有数据集洗牌问题。
ViT-B/16+ 使用 224 个 A100 (40 GB) GPU 训练了 ~61 小时,13620 个 GPU 小时。对于 35840 的全局批大小,每个 GPU 的批大小为 160。
ViT-L/14 224x224
L/14 LAION-400M 训练达到了 ImageNet-1k 零镜头验证得分 72.77 的前 1 名。
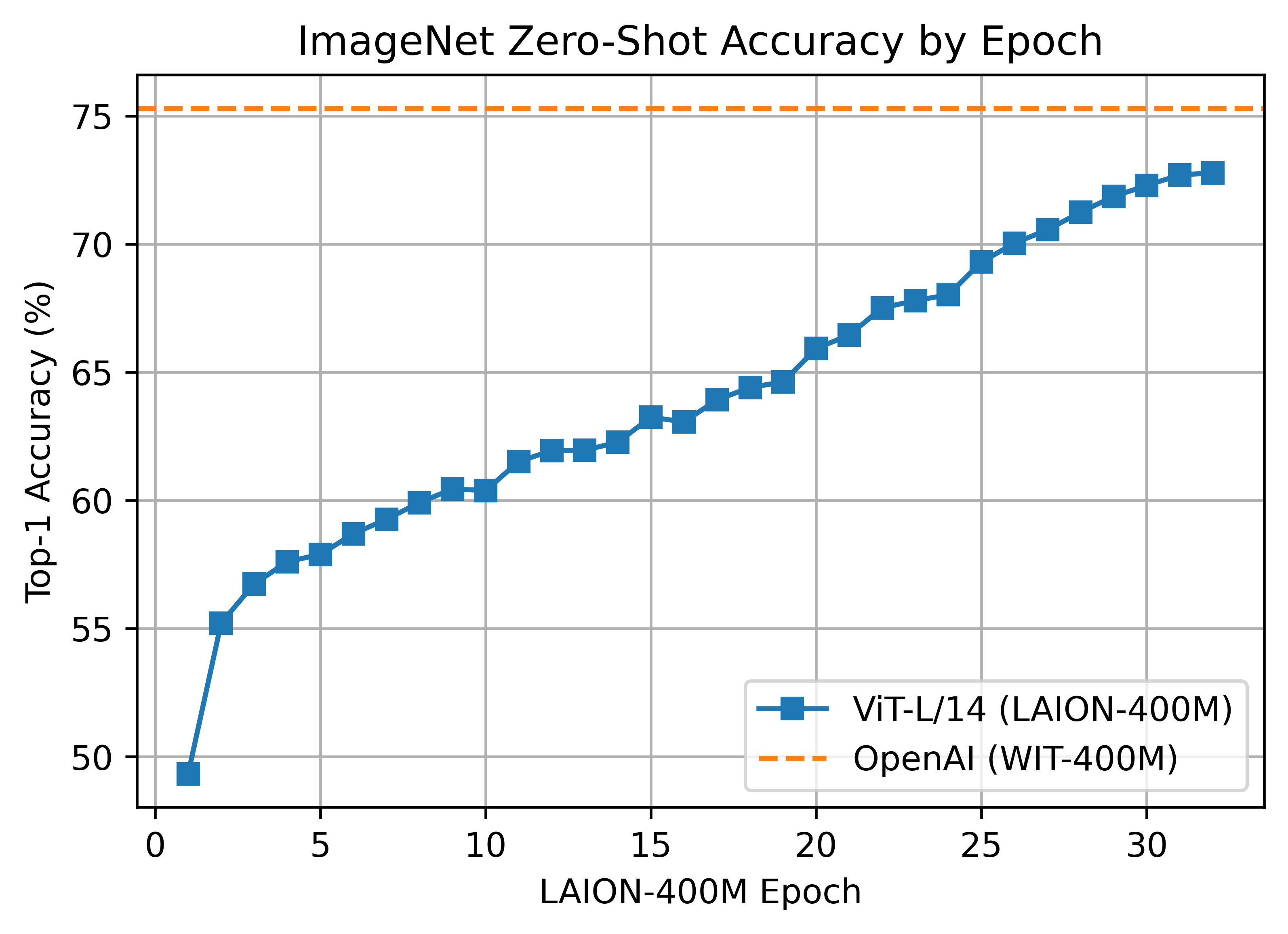
ViT-L/14 使用 400 A100 (40 GB) GPU 训练 ~127 小时,50800 GPU 小时。每个 GPU 的批大小为 96,全局批大小为 38400。已启用成绩检查点。
LAION-2B (英文) - https://laion.ai/laion-5b-a-new-era-of-open-large-scale-multi-modal-datasets/
LAION-5B 的 ~2B 样本子集,带有英文字幕 (https://huggingface.co/datasets/laion/laion2B-en)
ViT-B/32 224x224
一台 ViT-B/32 在 LAION-2B 上训练,达到了 65.62% 的 ImageNet-1k 零拍精度前 1 名。
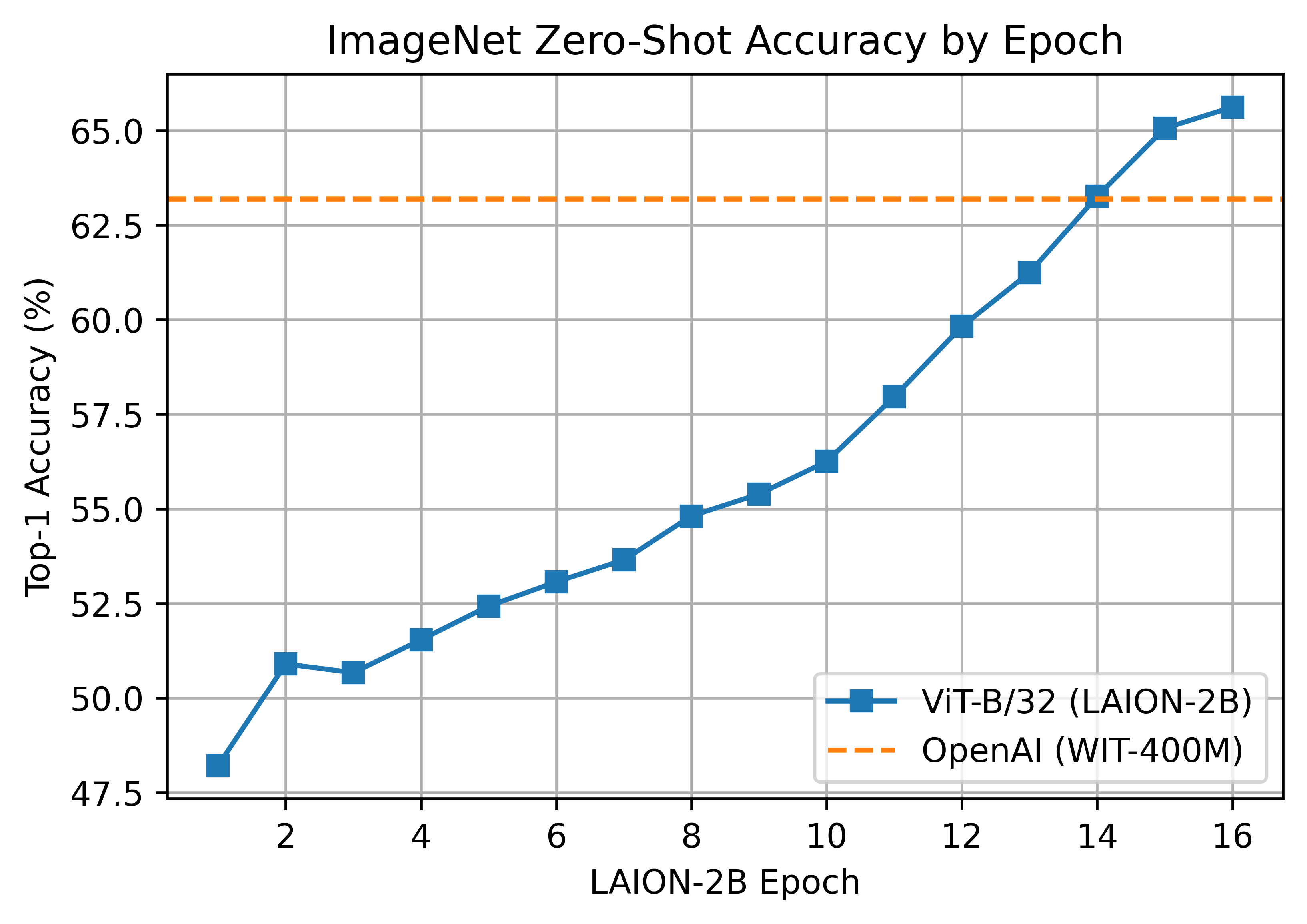
ViT-B/32 使用 112 个 A100 (40 GB) GPU 进行训练。每个 GPU 批处理大小为 416,全局批处理大小为 46592。由 stability.ai 慷慨地提供计算。
B/32 的第二次迭代是在具有较大全局批量大小和学习率 stability.ai 集群上进行训练的,达到 66.6% 的前 1 名。请参阅 https://huggingface.co/laion/CLIP-ViT-B-32-laion2B-s34B-b79K
ViT-L/14 224x224
具有75.3%前1名ImageNet-1k零镜头的ViT-L / 14在JUWELS Booster上进行了训练。在此处查看型号详细信息 https://huggingface.co/laion/CLIP-ViT-L-14-laion2B-s32B-b82K
这些权重使用与其他权重不同的数据集平均值和标准。不使用OpenAI均值和标准,而是通过均值和标准使用初始样式规范化。如果使用预先训练的权重,则会自动处理。
[-1, 1]
[0.5, 0.5, 0.5]
open_clip.create_model_and_transforms
ViT-H/14 224x224
具有78.0%top-1 top-1 ImageNet-1k零镜头的ViT-H / 14在JUWELS Booster上进行了训练。在此处查看型号详细信息 https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K
ViT-g/14 224x224
具有76.6%top-1 ImageNet-1k零镜头的ViT-g/14在JUWELS Booster上进行了训练。在此处查看型号详细信息 https://huggingface.co/laion/CLIP-ViT-g-14-laion2B-s12B-b42K
该模型的训练时间比其他LAION-2B模型更短,可以看到12B样本而不是32 + B。它与所见样本中的LAION-400M训练相匹配。因此,许多零镜头结果较低,但尽管如此,它在某些 OOD 零镜头和检索任务中表现非常好。
ViT-B/32 罗伯塔底座
带有 roberta 基础编码器的 ViT-B/32 具有 61.7% top-1 ImageNet-1k 零镜头的稳定性训练。在此处查看模型详细信息 https://huggingface.co/laion/CLIP-ViT-B-32-roberta-base-laion2B-s12B-b32k 这是第一个使用 HF 文本塔的开放式剪辑模型。与标准文本编码器相比,它在一系列任务上具有更好的性能,请参阅指标
{kind=link}
ViT-B/32 xlm 罗伯塔底座
带有xlm roberta基础编码器的ViT-B/32具有62.33%的top-1 ImageNet-1k零镜头,经过稳定性训练。在此处查看模型详细信息 https://huggingface.co/laion/CLIP-ViT-B-32-xlm-roberta-base-laion5B-s13B-b90k 这是第一个在完整的 laion5B 数据集上训练的 openclip 模型;因此,第一个使用OpenClip训练的多语言剪辑。与标准文本编码器相比,它在一系列任务上具有更好的性能,请参阅指标 进行了初步的多语言评估:对 imagenet1k 意大利语进行了 43%(英语 B/32 为 21%),imagenet1k 日语为 37%(英语 B/32 为 1%,B/16 剪辑日语为 50%)。它显示多语言属性确实如预期的那样存在。较大的型号将获得更好的性能。
{kind=link}
ViT-H/14 xlm 罗伯塔大
配备 xlm roberta 大型编码器的 ViT-H/14 具有 77.0%(英语等效值为 78%)的 top-1 ImageNet-1k 零镜头,经过稳定性训练。在此处查看型号详细信息 https://huggingface.co/laion/CLIP-ViT-H-14-frozen-xlm-roberta-large-laion5B-s13B-b90k
该模型按照LiT方法进行训练:图像塔被冻结(从英语openclip ViT-H / 14初始化),文本塔从xlm roberta大型初始化并解冻。这使培训成本降低了 3 倍。
查看完整的英语指标
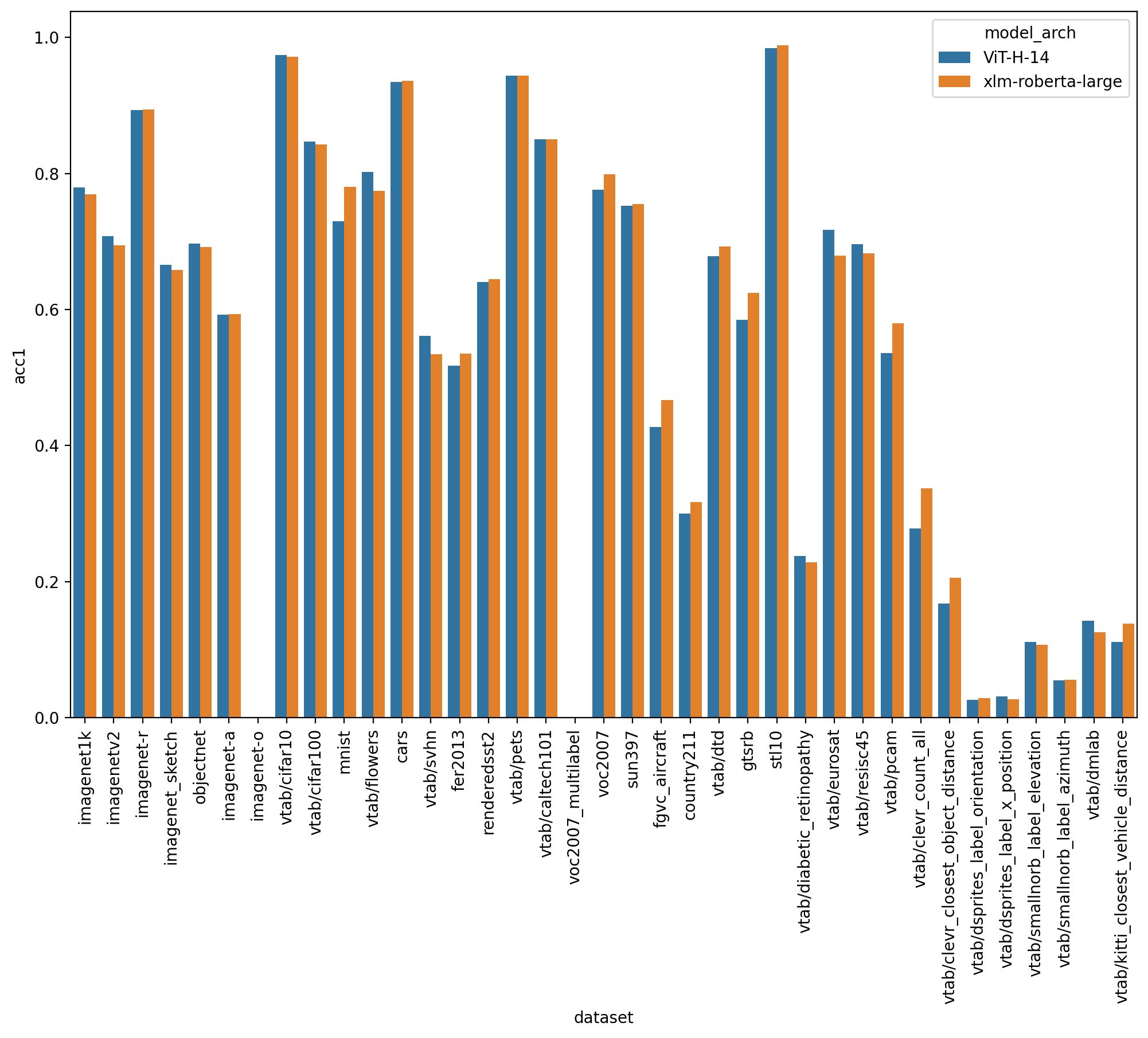{kind=link}
在带有翻译提示的图像网上的零镜头分类中,该模型达到:
- 意大利语为56%(https://github.com/clip-italian/clip-italian 为21%))
- 日语为53%(https://github.com/rinnakk/japanese-clip 为54.6%))
- 中文占55.7%(与 https://github.com/OFA-Sys/Chinese-CLIP 比较))
YFCC-15M
以下是在YFCC-15M上训练的模型的检查点,以及它们在ImageNet和ImageNetV2上的零镜头top-1精度。这些模型使用 8 个 GPU 和“示例运行代码”部分中描述的相同超参数进行训练,但 和 除外。
lr=5e-4
epochs=32
- ResNet-50 (32.7% / 27.9%)
- ResNet-101 (34.8% / 30.0%)
CC12M - https://github.com/google-research-datasets/conceptual-12m
- ResNet-50 (36.45%)
预训练模型接口
我们提供一个简单的模型接口来实例化预训练和未训练的模型。
注意:许多现有的检查点使用原始OpenAI模型中的QuickGELU激活。这种激活实际上比最新版本的PyTorch中的本机torch.nn.GELU效率低。模型默认值现在为 nn。GELU,因此应该使用带有后缀的模型定义来表示 OpenCLIP 预训练权重。所有 OpenAI 预训练权重将始终默认为 QuickGELU。也可以使用 QuickGELU 将非模型定义与预训练权重一起使用,但精度会下降,因为微调可能会在长时间运行中消失。
-quickgelu
-quickgelu
未来训练的模型将使用 nn。格鲁。
>>> import open_clip
>>> open_clip.list_pretrained()
[('RN50', 'openai'),
('RN50', 'yfcc15m'),
('RN50', 'cc12m'),
('RN50-quickgelu', 'openai'),
('RN50-quickgelu', 'yfcc15m'),
('RN50-quickgelu', 'cc12m'),
('RN101', 'openai'),
('RN101', 'yfcc15m'),
('RN101-quickgelu', 'openai'),
('RN101-quickgelu', 'yfcc15m'),
('RN50x4', 'openai'),
('RN50x16', 'openai'),
('RN50x64', 'openai'),
('ViT-B-32', 'openai'),
('ViT-B-32', 'laion400m_e31'),
('ViT-B-32', 'laion400m_e32'),
('ViT-B-32', 'laion2b_e16'),
('ViT-B-32', 'laion2b_s34b_b79k'),
('ViT-B-32-quickgelu', 'openai'),
('ViT-B-32-quickgelu', 'laion400m_e31'),
('ViT-B-32-quickgelu', 'laion400m_e32'),
('ViT-B-16', 'openai'),
('ViT-B-16', 'laion400m_e31'),
('ViT-B-16', 'laion400m_e32'),
('ViT-B-16-plus-240', 'laion400m_e31'),
('ViT-B-16-plus-240', 'laion400m_e32'),
('ViT-L-14', 'openai'),
('ViT-L-14', 'laion400m_e31'),
('ViT-L-14', 'laion400m_e32'),
('ViT-L-14', 'laion2b_s32b_b82k'),
('ViT-L-14-336', 'openai'),
('ViT-H-14', 'laion2b_s32b_b79k'),
('ViT-g-14', 'laion2b_s12b_b42k'),
('roberta-ViT-B-32', 'laion2b_s12b_b32k'),
('xlm-roberta-base-ViT-B-32', 'laion5b_s13b_b90k'),
('xlm-roberta-large-ViT-H-14', 'frozen_laion5b_s13b_b90k'),]
>>> model, train_transform, eval_transform = open_clip.create_model_and_transforms('ViT-B-32', pretrained='laion2b_s34b_b79k')扩展趋势
下图显示了 CLIP 模型的零镜头性能如何随着我们缩放用于训练的样本数量而变化。ImageNet 和 ImageNetV2 的零镜头性能稳步提高,并且在 ~15M 样本时远未饱和。
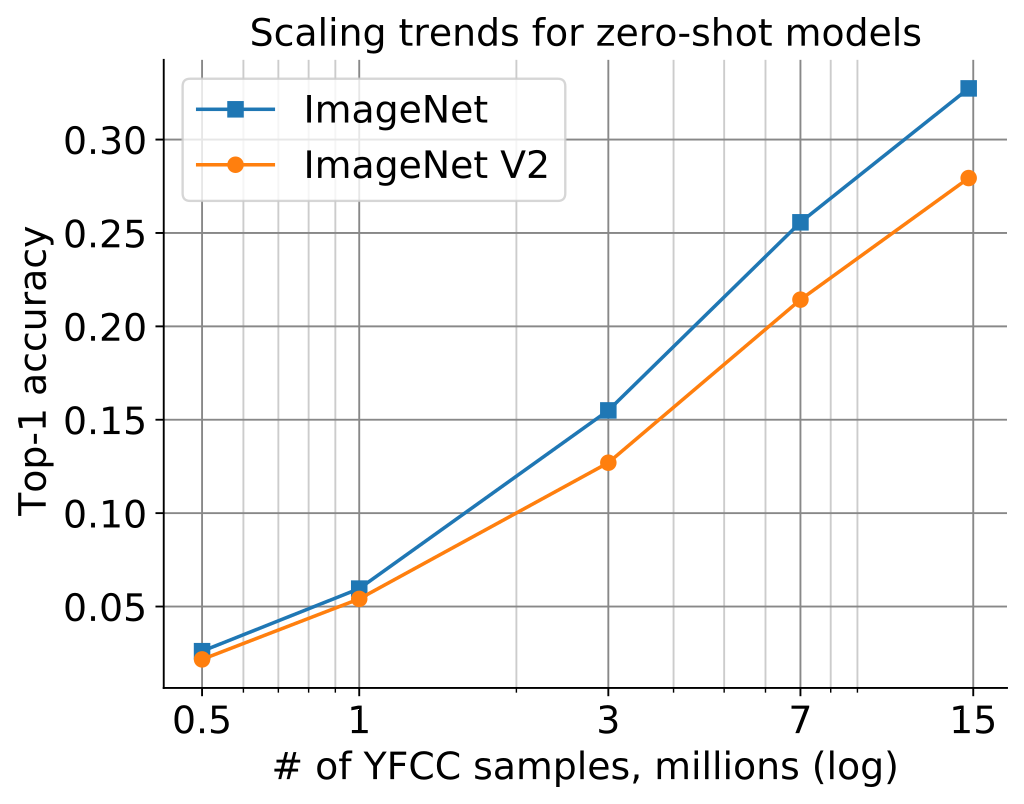
为什么低精度的 CLIP 模型很有趣?
博士:CLIP 型号即使在小尺度下也具有很高的有效鲁棒性。
CLIP模型特别有趣,因为它们对自然分布变化更具鲁棒性(参见CLIP论文中的第3.3节)。下图说明了这种现象,x轴上的ImageNet精度和y轴上的ImageNetV2(具有分布偏移的ImageNet验证集的再现)精度。标准训练表示在 ImageNet 训练集上进行训练,CLIP 零镜头模型显示为星号。
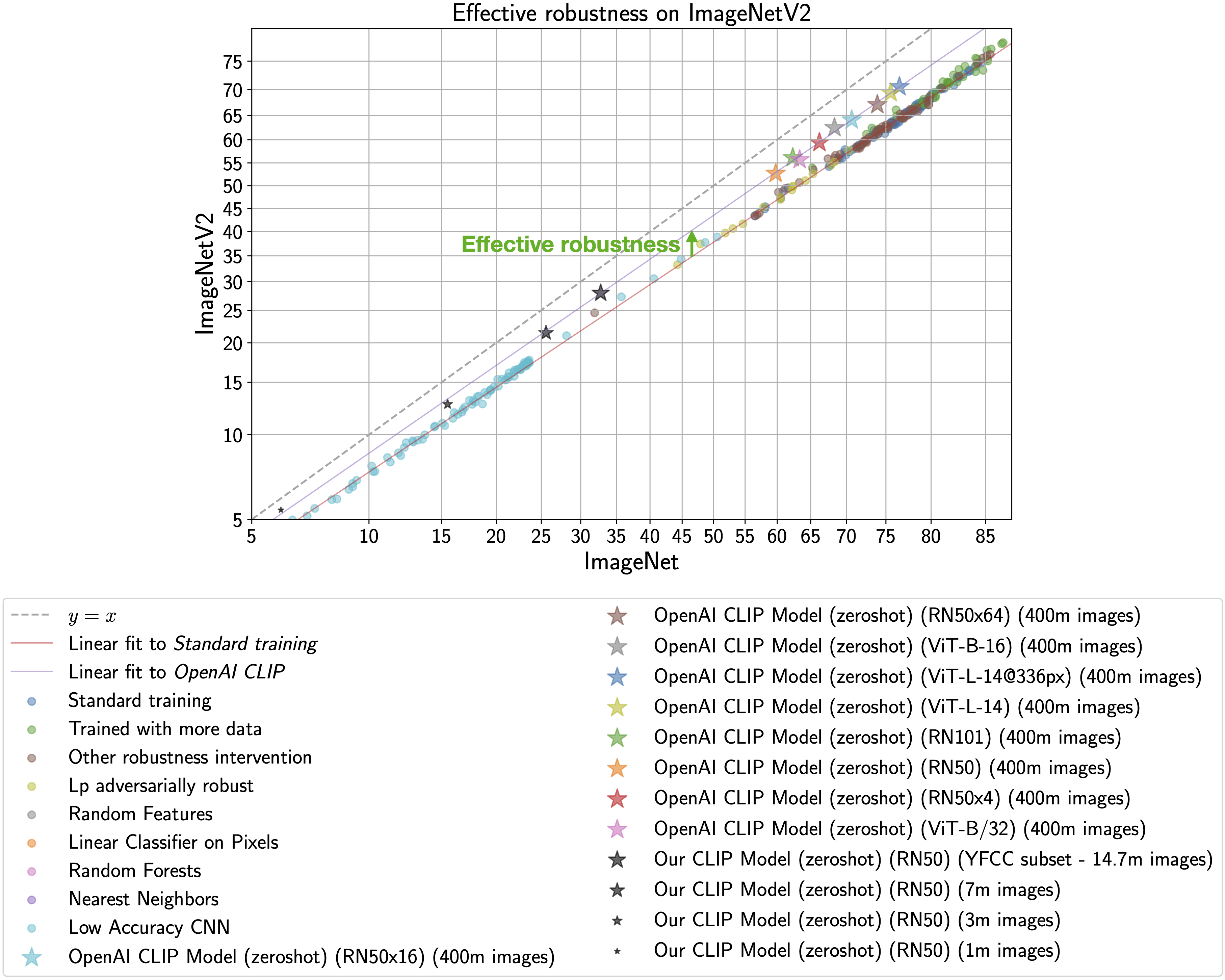
正如 Taori 等人(2020 年)和 Miller 等人(2021 年)所观察到的那样,在 ImageNet 上训练的模型的分布内和分布外精度遵循可预测的线性趋势(上图中的红线)。有效鲁棒性将鲁棒性量化为超出此基线的精度,即模型高于红线的距离。理想情况下,模型不会受到分布偏移的影响并落在y = x线上(训练有素的人工标记人员在y = x线的百分点内)。
尽管使用此代码库训练的 CLIP 模型的准确性远低于 OpenAI 训练的模型,但我们的模型仍然处于相同的有效健壮性改进趋势(紫线)。因此,我们可以研究是什么使 CLIP 具有鲁棒性,而无需工业规模的计算。
有关有效稳健性的更多信息,请参阅:
- 雷希特等人,2019 年。
- 陶织等人,2020 年。
- 米勒等人,2021 年。
要了解有关导致 CLIP 稳健性的因素的更多信息,请参阅 Fang 等人,2022 年。
确认
我们非常感谢高斯超级计算中心(www.gauss-centre.eu)通过约翰·冯·诺依曼计算研究所(NIC)在尤利希超级计算中心(JSC)的GCS超级计算机JUWELS Booster上提供计算时间,为这部分工作提供资金。
团队介绍
该存储库的当前开发由Ross Wightman,Cade Gordon和Vaishaal Shankar领导。
该存储库的原始版本来自UW,Google,Stanford,Amazon,Columbia和Berkeley的一组研究人员。
加布里埃尔·伊尔哈科*, 米切尔·沃茨曼*, 尼古拉斯·卡里尼, 罗汉·陶里, 阿查尔·戴夫, 瓦沙尔·香卡尔, 约翰·米勒, 洪锡南空, 汉纳内·哈吉希尔兹, 阿里·法哈迪, 路德维希·施密特
特别感谢Jong Wook Kim和Alec Radford帮助复制CLIP!
引用
如果你发现此存储库有用,请考虑引用:
@software{ilharco_gabriel_2021_5143773,
author = {Ilharco, Gabriel and
Wortsman, Mitchell and
Wightman, Ross and
Gordon, Cade and
Carlini, Nicholas and
Taori, Rohan and
Dave, Achal and
Shankar, Vaishaal and
Namkoong, Hongseok and
Miller, John and
Hajishirzi, Hannaneh and
Farhadi, Ali and
Schmidt, Ludwig},
title = {OpenCLIP},
month = jul,
year = 2021,
note = {If you use this software, please cite it as below.},
publisher = {Zenodo},
version = {0.1},
doi = {10.5281/zenodo.5143773},
url = {https://doi.org/10.5281/zenodo.5143773}
}@inproceedings{Radford2021LearningTV,
title={Learning Transferable Visual Models From Natural Language Supervision},
author={Alec Radford and Jong Wook Kim and Chris Hallacy and A. Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever},
booktitle={ICML},
year={2021}
}About
