OpenCodeInterpreter - OpenCodeInterpreter is a suite of open-source code generation systems aimed at bridging the gap between large language models and sophisticated proprietary systems like the GPT-4 Code Interpreter. It significantly enhances code generation capabilities by integrating execution and iterative refinement functionalities.
-
💡 Open Sourcing OpenCodeInterpreter-GM-7b Model with gemma-7b Base;
-
🚀 Deploying Demo on HuggingFace Spaces;
-
🛠️ Open Sourcing Demo Local Deployment Code with a Setup Guide
✨[2024-02-26]: We have open-sourced the OpenCodeInterpreter-DS-1.3b Model.
📘[2024-02-26]: We have open-sourced the CodeFeedback-Filtered-Instruction Dataset.
🚀[2024-02-23]: We have open-sourced the datasets used in our project named Code-Feedback.
🔥[2024-02-19]: We have open-sourced all models in the OpenCodeInterpreter series ! We welcome everyone to try out our models and look forward to your participation! 😆
OpenCodeInterpreter is a suite of open-source code generation systems aimed at bridging the gap between large language models and sophisticated proprietary systems like the GPT-4 Code Interpreter. It significantly enhances code generation capabilities by integrating execution and iterative refinement functionalities.
All models within the OpenCodeInterpreter series have been open-sourced on Hugging Face. You can access our models via the following link: OpenCodeInterpreter Models.
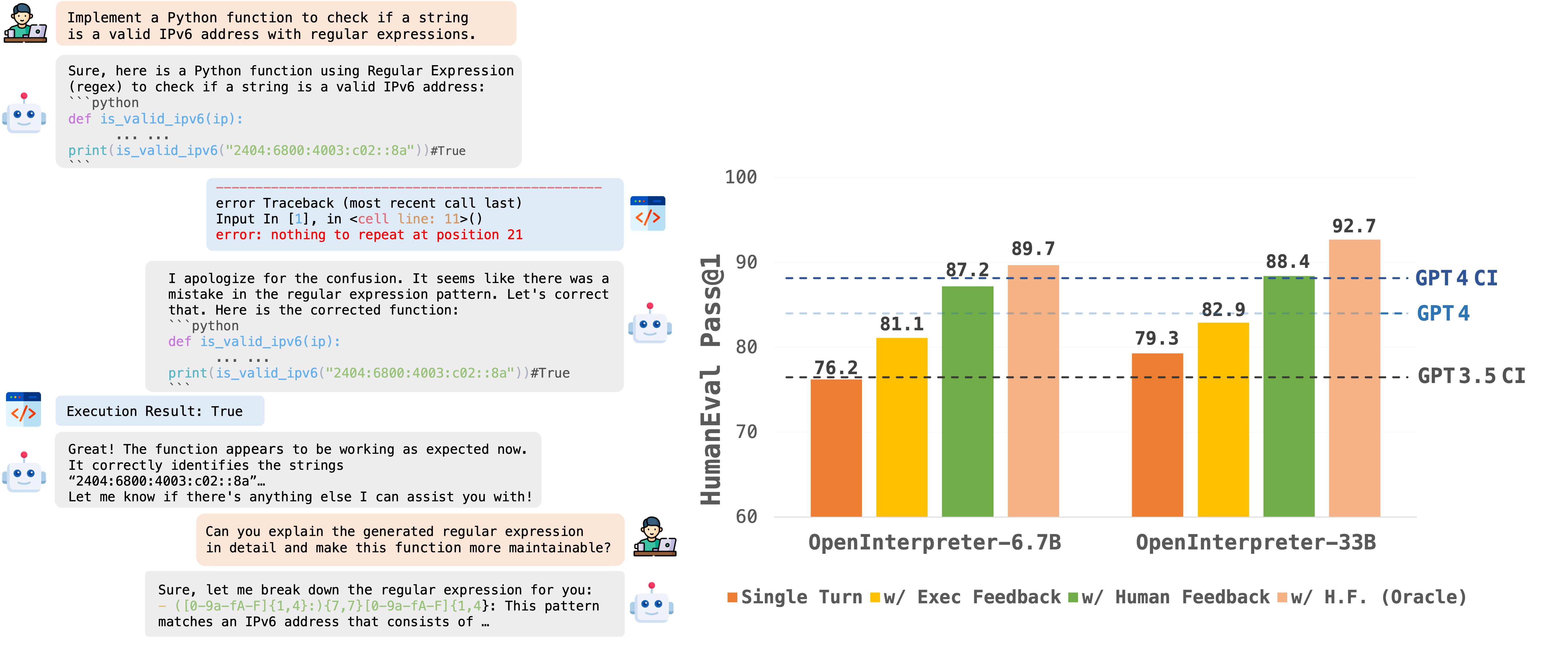
Supported by Code-Feedback, a dataset featuring 68K multi-turn interactions, OpenCodeInterpreter incorporates execution and human feedback for dynamic code refinement. For additional insights into data collection procedures, please consult the readme provided under Data Collection.
Our evaluation framework primarily utilizes HumanEval and MBP, alongside their extended versions, HumanEval+ and MBPP+, leveraging the EvalPlus framework for a more comprehensive assessment. For specific evaluation methodologies, please refer to the Evaluation README for more details.
If you have any inquiries, please feel free to raise an issue or reach out to us via email at: xiangyue.work@gmail.com, zhengtianyu0428@gmail.com. We're here to assist you!
About
