OpenCodeInterpreter - OpenCodeInterpreter:将代码生成与执行和优化集成
-
💡 开源 OpenCodeInterpreter-GM-7b 模型,带有 gemma-7b Base;
-
🚀 在HuggingFace空间上部署演示;
-
🛠️ 开源演示本地部署代码和设置指南
✨ [2024-02-26]:我们开源了 OpenCodeInterpreter-DS-1.3b 模型。
📘 [2024-02-26]:我们开源了 CodeFeedback-Filtered-Instruction Dataset。
🚀 [2024-02-23]:我们已经开源了名为 Code-Feedback 的项目中使用的数据集。
🔥 [2024-02-19]:我们已经开源了 OpenCodeInterpreter 系列中的所有模型!我们欢迎大家试用我们的模型,期待你的参与!😆
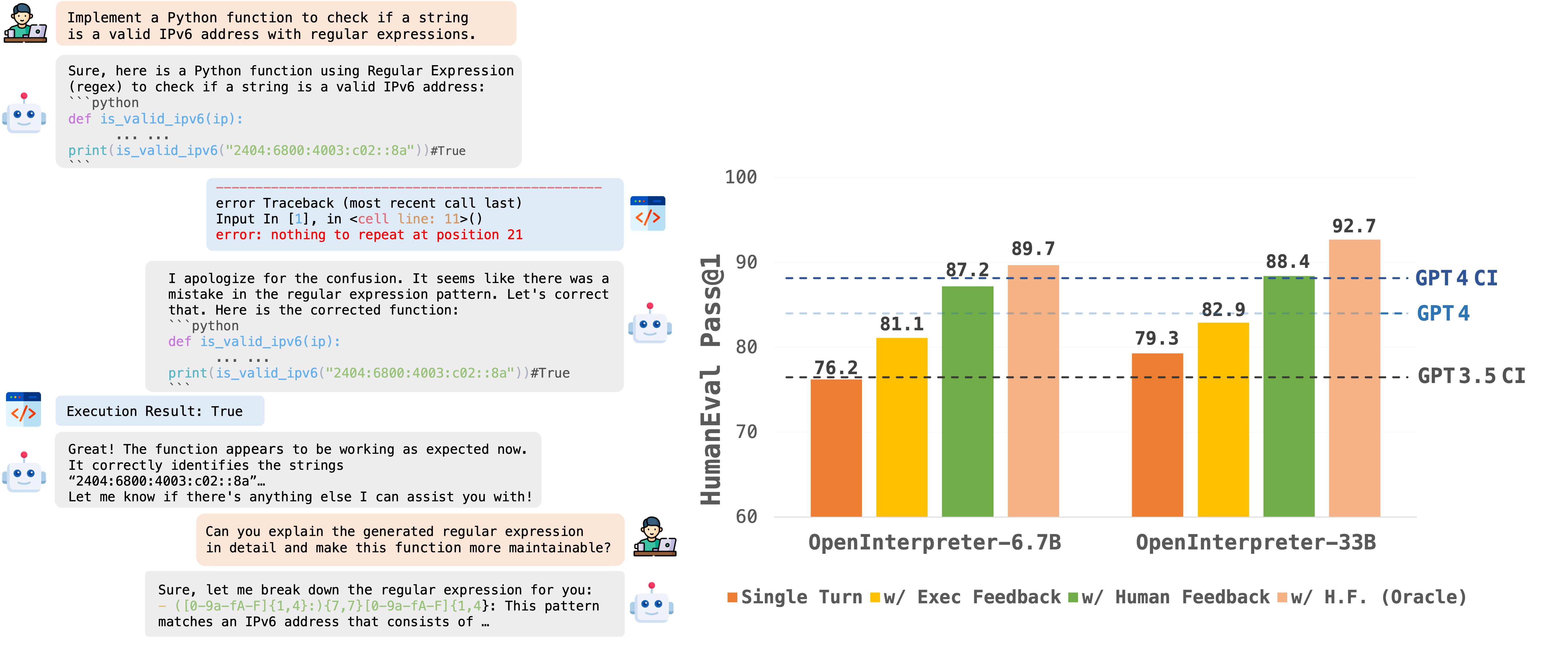
OpenCodeInterpreter 是一套开源代码生成系统,旨在弥合大型语言模型与复杂的专有系统(如 GPT-4 Code Interpreter)之间的差距。它通过集成执行和迭代优化功能,显著增强了代码生成能力。
OpenCodeInterpreter 系列中的所有模型都在 Hugging Face 上开源。你可以通过以下链接访问我们的模型:OpenCodeInterpreter 模型。
在 Code-Feedback(一个具有 68K 多轮交互的数据集)的支持下,OpenCodeInterpreter 结合了执行和人工反馈,以实现动态代码优化。 有关数据收集程序的更多见解,请参阅数据收集下提供的自述文件。
我们的评估框架主要利用 HumanEval 和 MBP,以及它们的扩展版本 HumanEval+ 和 MBPP+,利用 EvalPlus 框架进行更全面的评估。 有关具体评估方法,请参阅评估自述文件了解更多详情。
如果你有任何疑问,请随时提出问题或通过电子邮件与我们联系:xiangyue.work@gmail.com,zhengtianyu0428@gmail.com。 我们随时为你提供帮助!
About
