so-vits-svc-fork - so-vits-svc分叉具有实时支持,改进的界面和更多功能。
Created at: 2023-03-15 22:15:50
Language: Python
License: NOASSERTION
软VC VITS 歌声转换叉






具有实时支持和大大改进界面的so-vits-svc的分支。基于分支 (v1) 和模型兼容。
4.0
原始存储库中不可用的功能
- 实时语音转换(在 v1.1.0 中增强)
- 集成
快速VC - 修复了原始存储库中
ContentVec的误用。1 - 使用
CREPE进行更准确的螺距估算。 - 提供图形用户界面和统一命令行界面
- ~2 倍更快的训练
- 只需使用 进行安装即可使用。
pip
- 自动下载预训练模型。无需安装 .
fairseq
- 代码完全格式化为黑色,isort,autoflake等。
安装
一键轻松安装
此 BAT 文件将自动执行下述步骤。
手动安装
创建虚拟环境
窗户:
py -3.10 -m venv venv
venv\Scripts\activateLinux/MacOS:
python3.10 -m venv venv
source venv/bin/activateanaconda :
conda create -n so-vits-svc-fork python=3.10 pip
conda activate so-vits-svc-fork如果在程序文件中安装了 Python 等,则在不创建虚拟环境的情况下安装可能会导致 Python。
PermissionError
通过 pip(或你最喜欢的使用 pip 的包管理器)安装它:
python -m pip install -U pip setuptools wheel
pip install -U torch torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install -U so-vits-svc-fork笔记
- 如果没有可用的 GPU 或使用 MacOS,只需删除 即可。MPS 可能受支持。
pip install -U torch torchaudio --index-url https://download.pytorch.org/whl/cu118
- 如果你在 Linux 上使用 AMD GPU,请替换为 。AMD GPU 在 Windows 上不受支持 (#120)。
--index-url https://download.pytorch.org/whl/cu118
--index-url https://download.pytorch.org/whl/rocm5.4.2
更新
请定期更新此软件包以获取最新功能和错误修复。
pip install -U so-vits-svc-fork用法
推理
图形用户界面
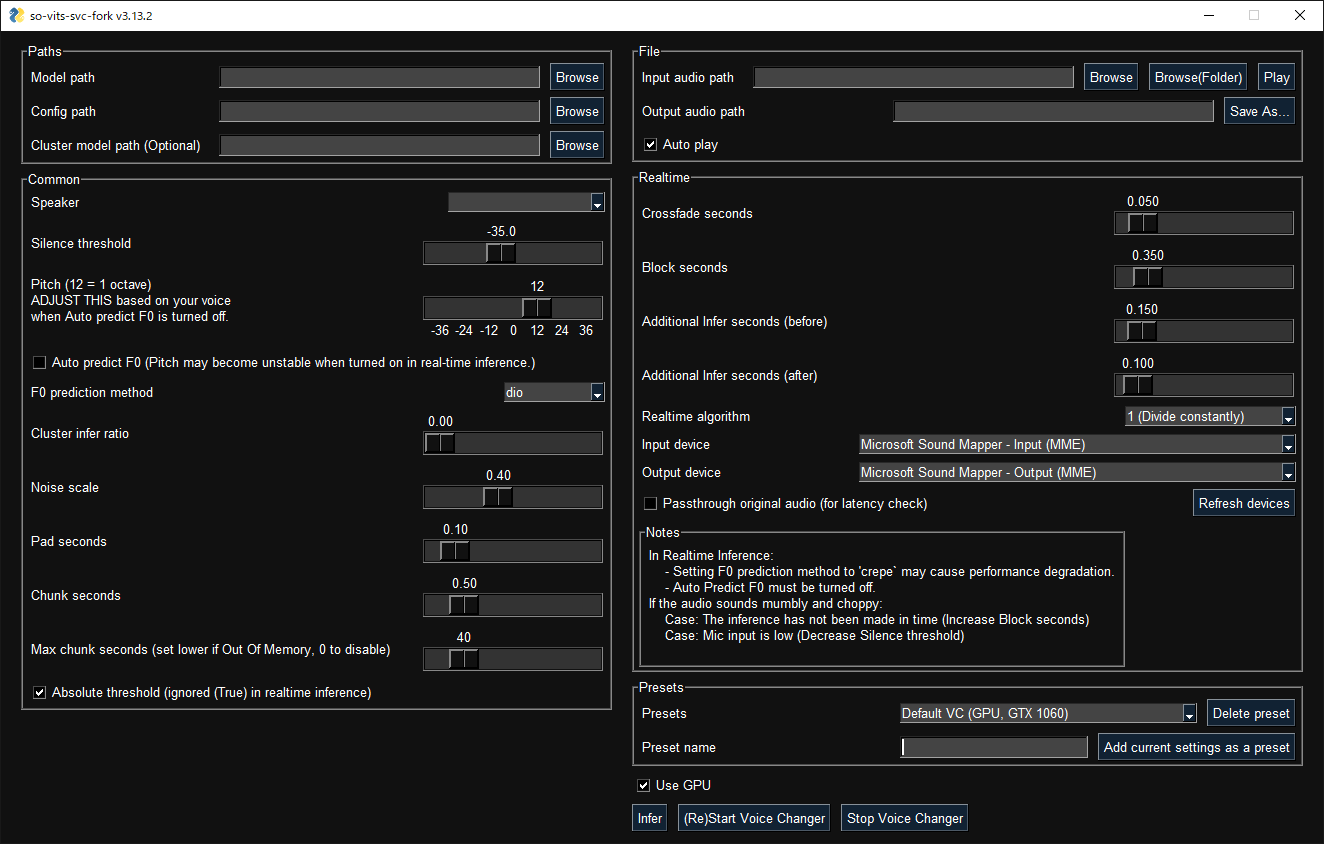
GUI 使用以下命令启动:
svcg佛罗里达州
- 实时(从麦克风)
svc vc- 文件
svc infer source.wav预训练模型可在Hugging Face或CIVITAI上使用。
笔记
- 如果使用 WSL,请注意,WSL 需要额外的设置来处理音频,并且 GUI 在未找到音频设备的情况下将无法工作。
- 在实时推理中,如果输入上有噪声,HuBERT模型也会对这些噪声做出 React 。在这种情况下,请考虑使用实时降噪应用程序,例如RTX语音。
- 不支持 4.0v1 或此存储库以外的模型。
- GPU 推理至少需要 4 GB 的 VRAM。如果它不起作用,请尝试 CPU 推理,因为它足够快。阿拉伯数字
训练
训练前
- 如果你的数据集具有 BGM,请使用终极人声去除器等软件删除 BGM。 或推荐。3
3_HP-Vocal-UVR.pth
UVR-MDX-NET Main
- 如果数据集是具有单个扬声器的长音频文件,请使用 将数据集拆分为多个文件(使用 )。
svc pre-split
librosa
- 如果数据集是具有多个扬声器的长音频文件,请使用 将数据集拆分为多个文件(使用 )。由于准确性问题,可能需要进一步的手动分类。如果说话者使用各种语音风格说话,请将 --min-speaker 设置为大于实际说话者的数量。由于未解析的依赖项,请手动安装:。
svc pre-sd
pyannote.audio
pyannote.audio
pip install pyannote-audio
- 手动对音频文件进行分类,可用。向上和向下箭头键可用于更改播放速度。
svc pre-classify
云
如果你无法访问VRAM超过10 GB的GPU,则建议轻度用户使用Google Colab的免费计划,对于重度用户,建议使用Paperspace的Pro/Growth计划。相反,如果你可以访问高端 GPU,则不建议使用云服务。
当地
放置数据集,例如(子文件夹和非ASCII文件名是可以接受的),然后运行:
dataset_raw/{speaker_id}/**/{wav_file}.{any_format}
svc pre-resample
svc pre-config
svc pre-hubert
svc train -t笔记
- 每个文件的数据集音频持续时间应为 <~10 秒。
- 需要至少 4GB 的 VRAM。5
- 建议在命令之前尽可能增加 in 以匹配 VRAM 容量。设置为 (或简单地 ) 将自动增加,直到发生 OOM 错误,但在某些情况下可能没有用。
batch_size
config.json
train
batch_size
auto-{init_batch_size}-{max_n_trials}auto
batch_size
- 要使用 ,请替换为 。
CREPE
svc pre-hubert
svc pre-hubert -fm crepe
- 要正确使用,请替换为 。训练可能需要稍长的时间,因为某些权重会因重用旧的初始生成器权重而重置。
ContentVec
svc pre-config
-t so-vits-svc-4.0v1
- 要使用 ,请替换为 。
MS-iSTFT Decoder
svc pre-config
svc pre-config -t quickvc
- 静默删除和卷规范化是自动执行的(如在上游存储库中),不是必需的。
- 如果已在大型无版权数据集上进行训练,请考虑将其作为初始模型发布。
- 有关更多详细信息(例如参数等),你可以查看 Wiki 或讨论。
进一步帮助
有关更多详细信息,请运行 或 。
svc -h
svc <subcommand> -h
> svc -h
Usage: svc [OPTIONS] COMMAND [ARGS]...
so-vits-svc allows any folder structure for training data.
However, the following folder structure is recommended.
When training: dataset_raw/{speaker_name}/**/{wav_name}.{any_format}
When inference: configs/44k/config.json, logs/44k/G_XXXX.pth
If the folder structure is followed, you DO NOT NEED TO SPECIFY model path, config path, etc.
(The latest model will be automatically loaded.)
To train a model, run pre-resample, pre-config, pre-hubert, train.
To infer a model, run infer.
Options:
-h, --help Show this message and exit.
Commands:
clean Clean up files, only useful if you are using the default file structure
infer Inference
onnx Export model to onnx (currently not working)
pre-classify Classify multiple audio files into multiple files
pre-config Preprocessing part 2: config
pre-hubert Preprocessing part 3: hubert If the HuBERT model is not found, it will be...
pre-resample Preprocessing part 1: resample
pre-sd Speech diarization using pyannote.audio
pre-split Split audio files into multiple files
train Train model If D_0.pth or G_0.pth not found, automatically download from hub.
train-cluster Train k-means clustering
vc Realtime inference from microphone外部链接
贡献 ✨
感谢这些很棒的人(表情符号键):
 34焦耳 |
 加勒特康威 |
 蓝色护身符 |
 一次性账户01 |
 緋 |
 洛德毛5 |
 DL909 |
 满意256 |
 皮耶路易吉·扎加里亚 |
 鲁库斯马特斯特 |
 德冢艺术 |
 heyfixit |
 书啮齿动物 |
 谢宇 |
 冷考菲 |
 斯伯西尔 |
 梅尔多纳 |
 莫德亚瑟 |
 阿隆丹 |
 利克兹 |
 胶带游戏 |
 何 |
 75奥苏 |
 托尼科82 |
 yxlllc |
 出嗝 |
 埃斯库里奥因格莱西亚斯 |
 布莱克辛格 |
 M.托伊布·安塔努萨 |
 埃克斯菲尔 |
 古拉农 |
 亚历山大·库米斯 |
 醋甲上 |
 海乌佩奇 |
 天蝎座 |
 马克西姆克斯 |
此项目遵循所有贡献者规范。欢迎任何形式的贡献!

热门github
1
2
4
The Python Risk Identification Tool for generative AI (PyRIT) is an open access automation framework to empower security professionals and machine learning engineers to proactively find risks in their generative AI systems.
(翻译:用于生成式 AI 的 Python 风险识别工具 (PyRIT) 是一个开放式访问自动化框架,使安全专业人员和机器学习工程师能够主动发现其生成式 AI 系统中的风险。)
5
7
8
9
Mamba is a new state space model architecture showing promising performance on information-dense data such as language modeling, where previous subquadratic models fall short of Transformers. It is based on the line of progress on structured state space models, with an efficient hardware-aware design and implementation in the spirit of FlashAttention.
(翻译:Mamba 是一种新的状态空间模型架构,在信息密集型数据(例如语言建模)上显示出良好的性能,而之前的二次模型在 Transformers 方面存在不足。它基于结构化状态空间模型的进展,并本着FlashAttention的精神进行高效的硬件感知设计和实现。)
10
11
13